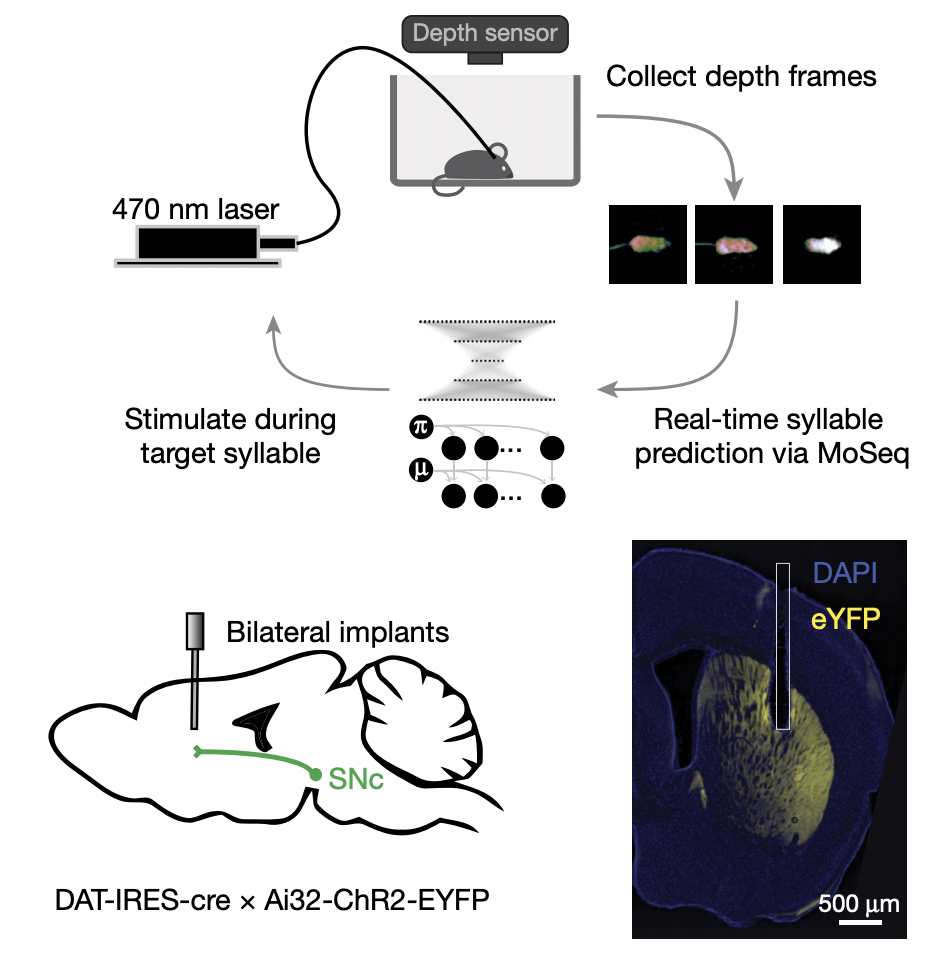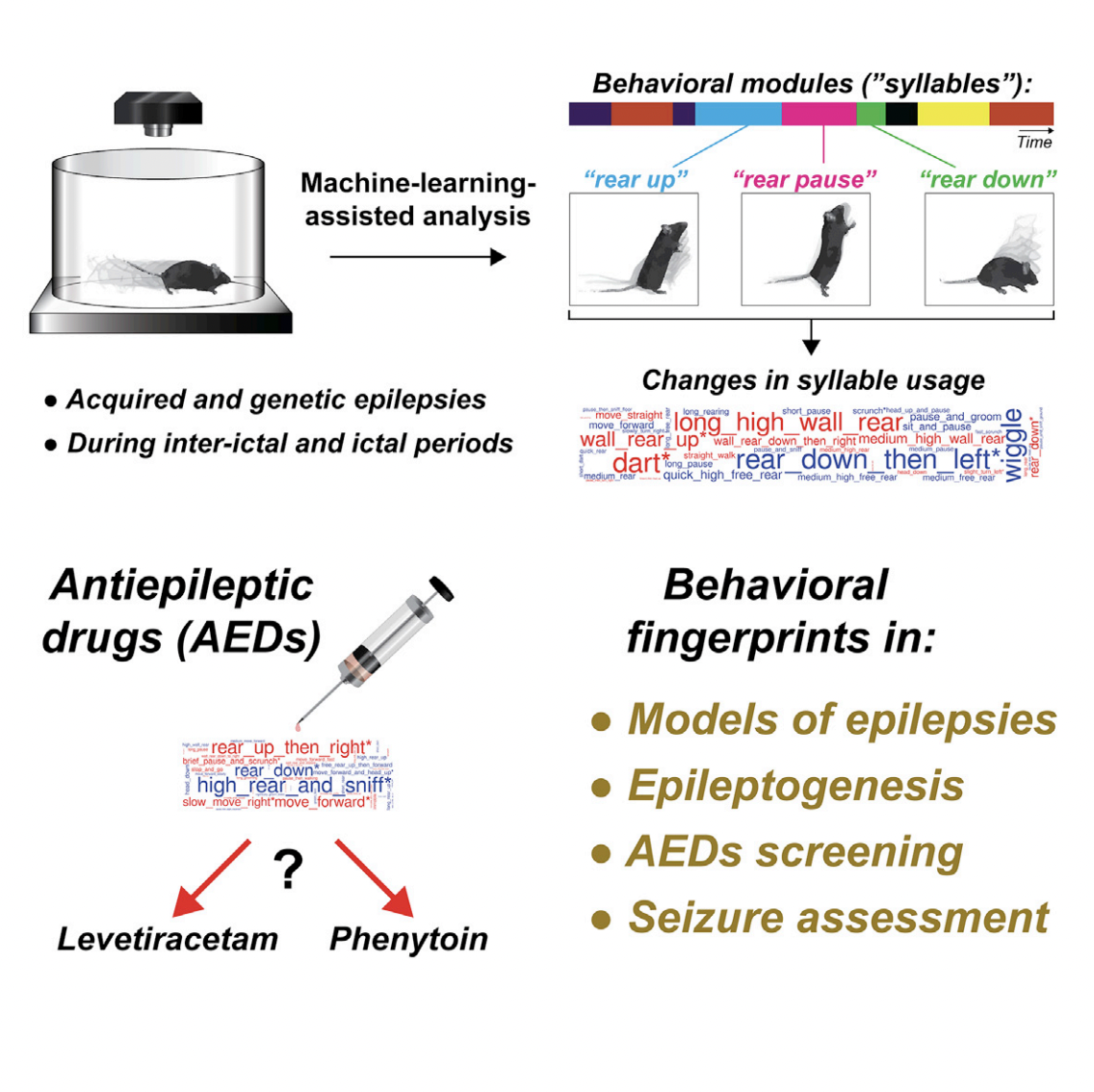
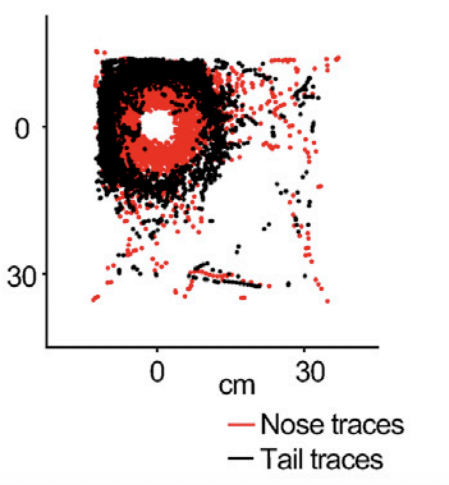
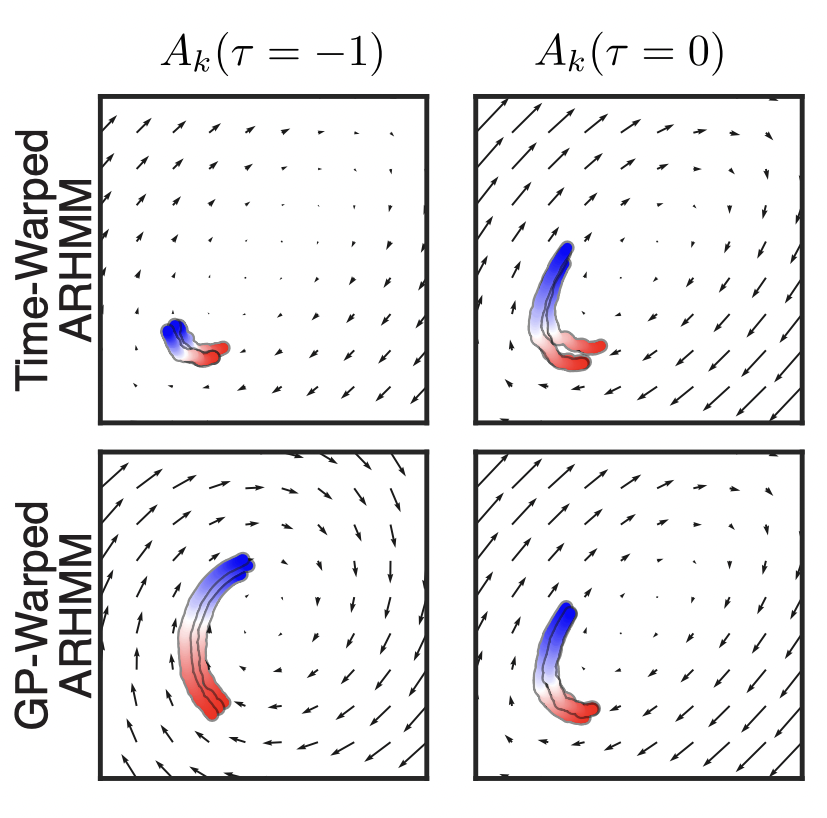
Advances in Neural Information Processing Systems July, 2022

We like to build tools and then use them to understand how the brain gives rise to action. As a lab we strive to do rigorous science while maintaining a fun, inclusive place to work.